

コンピュータによる意思決定支援
2010年7月30日
前回より筆者が大学時代に行っていた研究[1,2,3]について紹介しています。今回は、研究の概要について記します。
コンピュータが人の意思決定を支援する
前回、個人のキャリアを取り巻く状況と、個人のキャリアを効果的にサポートする3つのポイント、さらに、そのサポートのために人とコンピュータがそれぞれ得意な分野を分担することが重要だと述べました。これは、システムを設計、構築する際のみならず、自分で使用する際にも重要なポイントです。
この研究において、コンピュータが担う役割は、次の通りです。
- キャリアに関係があると思われる複数のデータベースのなかから、現在の目的に関連するデータベースを選択します。これにより、すべてのデータベースをまんべんなく調べたり、重要なデータベースへの問い合わせに漏れが生じたりすることが少なくなります。
- 膨大な量のデータベースから有益と思われる情報を収集して、任意の視点で関連の高いものから順番に提示します。これにより、すべての情報を精査する場合にくらべて、求める情報に到達するまでの時間を早めることができます。
- 別個に構築されている複数のデータベースから共通の目的に合致した情報を取得します。これにより、それぞれのデータベースに対して検索したり、検索結果を手動で編集、評価することなく、一回の検索で複数の情報源から情報を獲得することができます。
物理的な距離や時間に左右されず、効率的に情報を取得した結果、精度の高い評価や、創造的な編集、社会的な意味づけなど、人がクリエイティブな作業に注力することができます。
完璧な検索エンジンはない
完璧な検索エンジンというものはありません。データベースの研究においては、なんらかの制限や有効範囲を設けて、その条件のなかでは一定基準以上の精度の検索が可能である、ということを有効性や実現可能性の評価基準とします。しかし、それは、あくまで仮説の有効範囲内の閉じた世界のなかでのみ通用するものです。
さらに、このことを強く印象づけるのは、Googleの検索技術がヤフージャパンに対してライセンス提供されることになったことです(2010年7月27日発表)。ヤフーは、米国においてもマイクロソフトの検索エンジンBingを採用することを発表しています。これらのことは、一般的な検索エンジンに用いられてきたキーワードのパターン・マッチング技術、すなわち「同じキーワードを含むウェブサイト間は関連性が高い」という仮説の下に構築されてきた検索技術の進歩が上限に近づいてきているということを表しているように思います[4]。
このような現状に対する試みとしては、「GoogleやYahooのような検索エンジンにおける検索結果を正しいものとした上で、高度な編集・分析機能をつけ加えることで、情報へのアクセスが容易になる」という仮説のもとで、クラスタリングするなどして高度に分析した検索結果を出力してくれるもの[5]や、一方で、「検索可能なターゲットとなるウェブサイトの量が増えれば、重要な情報にたどり着く確率が向上する」という仮説ものもとで、WWWで公開されている情報のうち単純な巡回プログラムでは検索エンジンに登録(インデックス化)できない情報まで扱おうとするDeep Webと呼ばれる技術[6]もあります。
また、一見原始的にも見えますが、検索技術の限界を自覚した上で、その半分を人に委ねようというアプローチも採られています。ソーシャル検索サービスのAdvarkは、「最適な人や専門家に質問し直接回答を得るのが効率よく情報を得る方法である」という仮説のもとで、精度の高い検索結果を得るために、あるユーザの質問のテーマに合致するほかのユーザを、プロフィールをもとに自動で捜し出して手動での回答を促します[7]。
意思決定を支援するアプローチ
一人企業の基本的なコンセプトに影響を与えたこの研究成果は、上記のように、高度な分析機能を追加したり、情報収集量を増やしたり、ソーシャルな手法で人力を取り入れたりするのとは異なり、対象とする分野を絞って検索の精度を上げようというアプローチに基づいています。ここでの仮説は、「一定の(専門的)視点から対象となるデータベース群を評価すれば、対象となる情報源が多岐の分野の情報源であっても、その視点からみて重要な情報を特定できる」というものです。
この「特定の分野の一定の視点」を定義するものが、職業や人材に関する包括的な知識体系と語彙を定義したO*NET[8]のContent Modelです。ここでは、すべてのKnowldge(専門知識)は33種類に、Skills(技能)は35種類に、Abilities(基礎能力)は52種類に構造的に分類可能であるとした知識体系が定義されています。
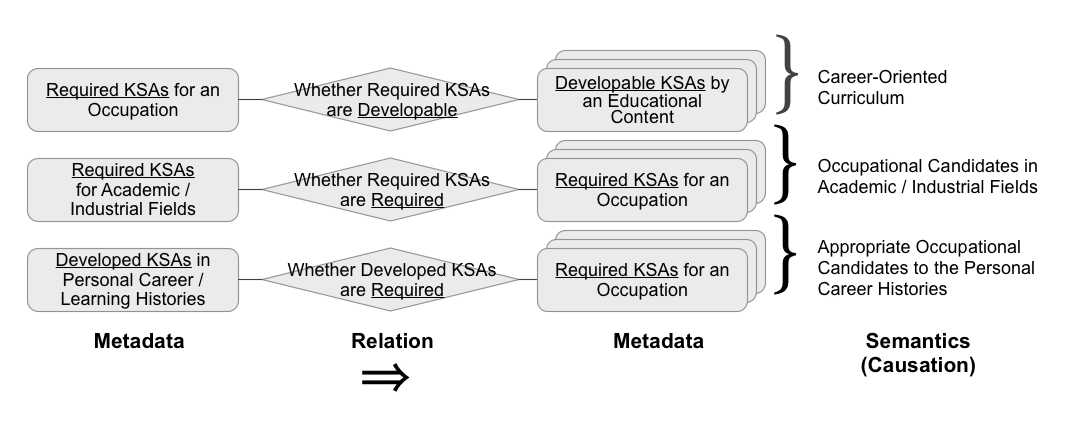
図1. 互いに異なるデータベースに対して職業や人材の分野からみた意味づけを行うことで、意味のある関連づけを行うことができるようになる。
この合計で120種類のKSAs(Knowledge,Skills and Abilities)を用いて、たとえば、BiologyやMathematicsといった専門知識(Knowledge)が、ある分野や職種において「必要とされているか(Required)」、授業や書籍といった教育コンテンツによって「修得が可能か(Developable)」、キャリアの履歴として「修得済みか(Developed)」という基準で評価することで、互いに異なるデータベース間で、職業や人材の分野からみた関連づけを行っています。この異なる意味の組み合わせにより、「カリキュラムデザインの意思決定支援(「教育分野」に対して関連の強い「教育コンテンツ」)」や「キャリア設計の選択肢の提示(「キャリア履歴」に対して関連の強い「職種群」)」などの意味を与えることができるようになります(図1)。
これを、既存の教育コンテンツ、教育における分野や課題、職業情報、個人のキャリアにおける履歴と目標に関するデータベース群の相互の関係を計量するメタレベル計量系(上位層での計算システム)と呼んでいます。
この研究で解決しようとしている課題は、すべての意思決定(decision making)をコンピュータに委ねて、計算結果としての出力の是非を評価するのではなく、対象となる情報を絞らずに、視点を提供する分野を絞ることで、あたかもその分野の専門家に相談しているかのような環境を作り出すことによって最適な意思決定の支援(decision support)をすることが目標です。
参考文献
- [1] Takahashi, Y.: “A Meta-Level Knowledge Base System for Connecting Educational and Occupational Databases with Semantic Transportation”, Keio University, Ph. D. Dissertation (2009).
- [2] Takahashi, Y. and Kiyoki, Y.:“A Meta-Level Knowledge Base System for Discovering Personal Career Opportunities by Connecting and Analyzing Occupational and Educational Databases”, Information Modeling and Knowledge Bases (IOS Press), Vol. XX, pp.270–289, 2009.
- [3] 高橋雄介, 清木康:“異種の職業情報と教育情報を連結するメタレベルデータベースシステムの構成方式”, 日本データベース学会論文誌, Vol.5 No.4, pp.29–32, 2007.
- [4] “Yahoo! JAPAN のより良い検索と広告サービスのために,” Google Japan Blog, http://googlejapan.blogspot.com/2010/07/yahoo-japan.html, 2010年7月27日.
- [5] Yippy (Clusty), http://search.yippy.com/.
- [6] DeepDyve, http://www.deepdyve.com/.
- [7] Advark, http://vark.com/.
- [8] The Occupational Information Network (O*NET), http://www.onetcenter.org/.